
By Scott Downie
I’ve read countless books and blog posts that cover specific aspects of development, and many other articles that talk at length about modularity, coupling, dependency inversion, SOLID, etc; but I’ve found it difficult to find many sources that discuss architecture in concrete rather than abstract terms, so thought I would share some of my own experiences. Architecture is more than just the modules of your application (although that is a big part of it), architecture is the relationship between those modules and particularly the data that those modules consume and produce in order to achieve the product vision. Architecture is also not something that should be rigid but something that should change as our understanding of the product space changes. It is unreasonable to expect us to plan and deliver a game on the first iteration without encountering challenges, feedback, misassumptions that then ultimately force us to change our approach.
At Tag I’ve been fortunate enough to work on a number of different greenfield projects, each providing me and the teams with an opportunity to try something different and attempt to learn the lessons of the past. In the last couple of years I’ve kind of settled on a general approach that we’ve used in our last 3 or 4 projects (although it may change in future again - who knows). Tag isn’t a hive-mind, so there are people I work with day to day who I’m sure (and in some cases know) would approach things differently. But equally there are a number of people who are philosophically aligned with me. So all of that is just to say this is a reflection of my thoughts and experiences that I wanted to get down on paper (others on the team will also have a chance to post about things that are important to them).
This post will focus primarily on architecture through the lens of building a codebase that is “responsive to change”, so that we can accommodate the inevitable pivots and bumps in the road with as little additional impact as possible. There are, of course, other important facets of designing a codebase: like how it supports performance, how we utilise and support a larger team, etc, that I’ll perhaps cover in future - but for now the focus is on adaptability. (Worth noting that I don’t believe performance, readability and adaptability are mutually exclusive - but that’s for another day). The aim of writing this was both to help set out my approach for those who might be curious and hopefully prompt some discussion about what has and hasn’t worked for others. So I’m interested in hearing others' experiences, thoughts and feedback.
Something worth noting is that I will try to avoid using shorthands to refer to patterns and instead build from first principles to avoid any misunderstanding. I find it hard enough to build alignment using shorthands within a team working together day to day, let alone have shorthands that translate to a global audience. I tend to think of good shorthands as something that emerge over time once there is alignment on the foundational knowledge.
Responding to change
Humans tend to be inherently anxious about change and I’ve found that to be particularly true with programmers (myself included), who seek order and often see change as chaotic. Sometimes we find ourselves in situations where the design is changing and we lament the fact we didn’t do more to catch this up front and plan for it. But deep down we know that change is inevitable and often outwith our control. Whether it is coming up against something unexpected in an implementation, pivoting the design in response to user feedback, or even sometimes having to change to support platform or legal directives. The requirements that our codebase supports at the start of a project will not be the same requirements it needs to support at the end - and that is ok.
So what does it mean to be responsive to change? Or rather what does it not mean? In my opinion being responsive to change does not mean our code can magically handle changes in design. I’m a strong believer that non-trivial changes in the design domain should result in similar scope changes in the actual codebase. Being responsive to change is about reducing the time and impact of making those changes. In essence, how reconfigurable our code is and how easy it is to remove parts that no longer meet the requirements and replace them with parts that do.
This is sometimes in conflict with the (often preferred) approach of writing more “generic” solutions upfront. While there are valid cases for writing more general purpose solutions, I’m a big believer that these tend to be more exceptional cases and for most problems it is better to focus on solutions that are a tight fit for the concrete requirements at hand. The reasons being that “generic” solutions tend to:
Have larger upfront and ongoing maintenance costs
Be more complex than a tight fitting solution (not always and that can be a good razor for choosing that approach)
Miss the mark (when applied speculatively), introducing unhelpful coupling or not actually handling the evolving requirements.
So I’ve kind of developed a heuristic that if non-trivial changes in design don’t require changes in the code, that is a bit of a red-flag that we might be solving problems more generally and are perhaps falling foul of confirmation bias for the handful of general purpose solutions that have worked out. All in all I tend to follow the “rule of three” with regard to generic code - if we have 3 concrete examples that point to a more general purpose solution; we can then build the more general purpose solution.
In terms of architecture that is responsive to change, to me this means we build something that doesn’t try and guess at how the product will evolve, it supports the product as the product is now - but crucially reduces the cost of changing the modules and the relationships between modules as we learn more about the design domain.
So how do we measure how responsive to change our codebase is? I could probably fill a whole blog post with a discussion of the importance of objective measurements but I’ll just say that it is important that where possible we try to approach these things in terms of measurable outcomes. While it is very difficult to say whether one architecture is “better” than another, we can absolutely say whether our architecture meets the measurable outcomes. So let’s define the measurable outcomes for a codebase that is responsive to change:
Responsive to change
Minimises time taken for changes in the design to be reflected in actual working software
Minimises the amount of bugs and technical debt taken on to achieve that change
Maintains the product KPIs despite changes
We should measure these periodically and if these KPIs get worse as the design changes, then chances are our structure isn’t adaptable enough…yet. But it can and should evolve.
The 5 principles
We need to split our codebase up so that it is easier to rationalise about, can support multiple people working on it and ultimately, so that it is easier to make changes to the codebase in response to changes in the design domain.
Now we can talk about “modularity” and the role that it plays in helping us respond to change. After all, architecture is primarily about designing the relationships between modules. Essentially the idea is to make it so modules can be easily changed, or replaced, and crucially for the relationships between modules to change - without the ripples of that impacting on the wider codebase (or the wider team).
We achieve this through these main principles/guidelines:
Organise the application into “phases” and “layers”. Where the “phases” encapsulate systems and data relating to that phase of the application and the dependencies between layers are unidirectional
Centralise “global” data outside of any one system
Minimise inter-system dependencies using “data contracts” and have them communicate through a “glue layer” / coordinator (which we call Flow States BTW)
Ensure “global” state changes are enacted centrally and not through satellite systems
Model the behaviours and not the design domain
Here’s a simple, hopefully very recognisable scenario. We have a player controlled character (controlled via some input device) that moves around the world and the camera follows its position. Here’s a diagram showing the architecture:
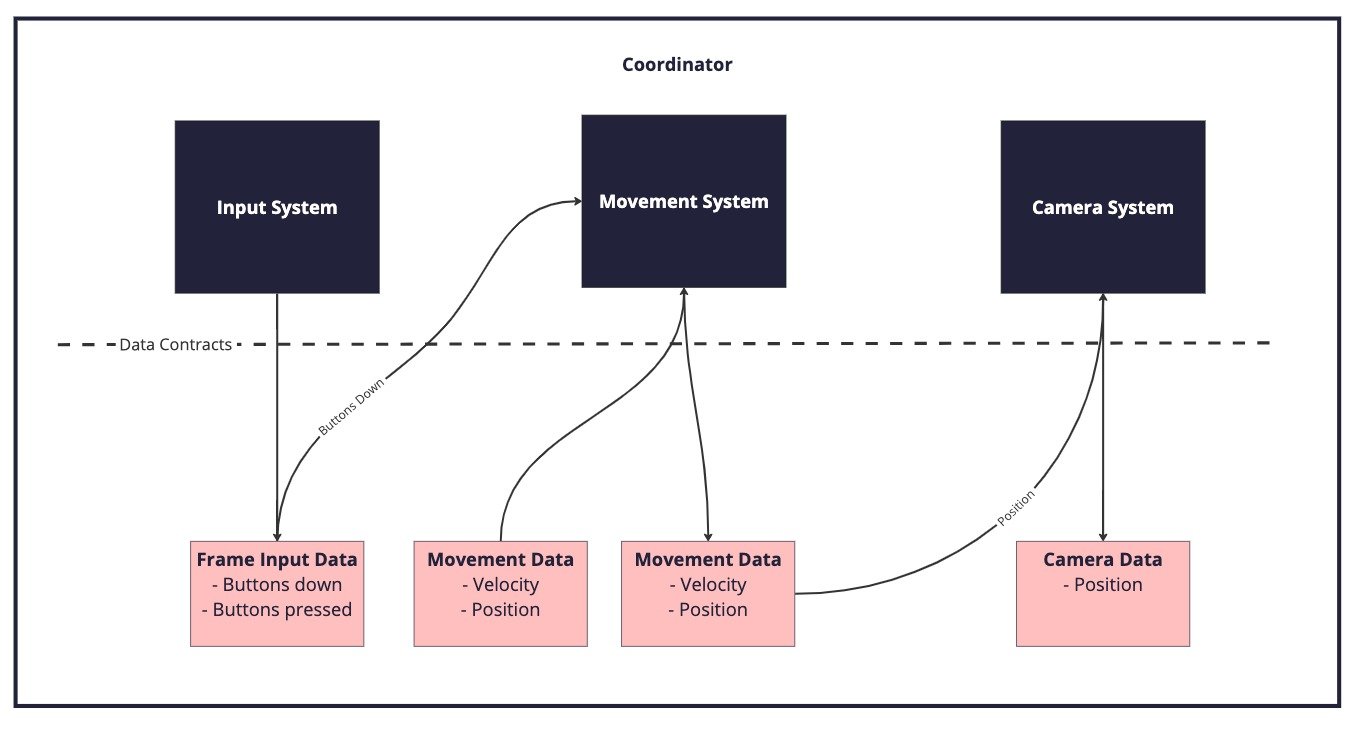
Let’s walk through how the principles are applied.
#1 Organise applications into “phases” and “layers”
Let’s start by thinking about our application in terms of discrete phases; perhaps there is a main menu and then the game itself (the above diagram captures a system operating in the “game” phase). You could imagine each of those phases having a “coordinator” that drives the systems and the data flow for each phase, as well as holding onto the relevant core data for the phase. You can think of the “coordinator” as being the conductor of an orchestra; not making any of the music but making sure everything else is happening at the right time. If we just have a single coordinator it would soon become giant and unwieldy with systems running that aren’t even needed at that point in time. We will likely want to split some of these phases into smaller finite states - perhaps “game” is actually made up of an “attacking” mode and a “defending” mode. Each mode runs different systems, has different data and has different UI views, but there are still some “game” phase wide systems (like listening for a “pause” event) that we want to run in both modes. So now we have something of a hierarchy where “attack” and “defend” coordinators are actually children of the “game” coordinator and each system within the coordinator is also a bit like a child.
Firstly, we want to avoid children having dependencies on parents or parent systems. Doing this will make it more difficult for something like a UIView or other systems to be used in multiple phases because they will be coupled together with a specific phase. This coupling impacts on adaptability because there is more work to be done if we want to move the system or view to another phase of the application. So it’s fine for a coordinator to call a function on a system (say to update it each frame) but typically we want to avoid explicit dependencies the other way around. These boundaries can be quite obvious at a library level where it would be fine for our “MainMenu” to depend on a JSON parser but certainly not fine for the JSON parser to depend on our “MainMenu”. (FYI we touch on handling this dependency inversion a little later but it can be achieved in multiple ways.)
Secondly, we want to ensure that the “coordinator” has all the information it needs to make any required global state changes (#4). If a coordinator is too low down the hierarchy to make an effective decision, then the decision needs to be escalated up the hierarchy until a coordinator has the context to act on the information. So for example if the “attacking” coordinator wants to show a UI screen but we know that the parent “game” coordinator manages the pause screen - it probably makes sense to promote the management of the screen state to the “game” coordinator. In practice this means as the application evolves data stores are promoted and demoted up and down the hierarchy to make sure that coordinators have all the information they need for their systems.
#2 Centralise “global” data
I’ll start by trying to define “global” data. It’s not in reference to global variables or anything like that; but more that we have data that is important or central to our application and that is often required by multiple systems. A good example is the position of the player. In our small scenario above, the player position is important to the CameraSystem and the MovementSystem but it will equally be important to a collision detection system and UI systems (for displaying markers, etc). If we squirrel that data away inside systems - especially satellite systems - then we will likely introduce dependencies between different systems (see #3) but equally as the design of the application shifts you might find that the data needed by systems only exists in places that there isn’t a direct connection to. The solution is then often to convert those systems to singletons to provide easy access to the data, but this can then lead to “the big ball of mud” pattern, where the convenience of having access to systems anywhere leads to a loss of structure as systems start to call into each other. Another solution that emerges to solve the lack of direct access to data is the introduction of complex dependency inversion through message passing. Messaging passing has its uses (which I touch on later) but not as a sticking plaster for poorly designed communication lines. Ultimately message passing adds a layer of cognitive load in tracking where the messages come from. For me it is better to accept that there is data in our application that doesn’t really belong to any one system but instead belongs more centrally in some form of data storage container (BTW, I’m also not saying systems can’t be stateful, they will have internal working/scratch data that only they care about).
If we have the data stored centrally in the coordinators (not necessarily as literal variables but in some data container) when we add a new system (or change the responsibilities of an existing system) we should then easily be able to feed it the data it needs. The coordinator can even aggregate/package/split data into the format needed by the systems (not too dissimilar to the controller in a Model-View-Controller approach). So if required there can be a level of indirection between the stored data layout and the layout needed by systems. Now, typically we will want the data stored in batches and formatted ready to give to the systems in bulk without any transformations - but different systems might require the data in different formats and we will probably want to layout the data around the critical path. Ideally we will want to group data together so that it has high cohesion (i.e. 90%+ of the data elements are used by any given system that uses that data container).
In many respects this sort of database approach is what would happen in a typical server application, where logic and data is very much decoupled. It also has the advantage of being more trivial to serialise if we aren’t spreading the responsibility of serialisation across multiple otherwise unrelated systems.
#3 Minimise inter-system dependencies with “data contracts”
Notice in the diagram above that the systems do not have any direct dependencies on each other. Sometimes I’ve seen this achieved using interfaces at a system level, to avoid creating explicit type dependencies between two systems, but that approach doesn’t really solve the main problem as we still have the dependencies on the actual interface via the method calls. The systems in our example above essentially just take in some data and output some data (our result). This means we can change the internals and even the API of the InputSystem without having to touch the MovementSystem. The MovementSystem just needs the previous frame’s velocity and position, it doesn’t care how that data is provided. So if we need to change the wider application in response to some design change - as long as we still provide velocity and position, the MovementSystem is quite happy. This is important because there is a correlation between the amount of churn in a system (frequency of changes) and the number of bugs. By reducing the reasons for the MovementSystem to change, we hopefully also reduce the number of bugs.
I refer to this boundary between systems as “data contracts”, by which I mean there is an exchange of data under an agreed format. Another benefit in establishing these “data contracts” is that we can iterate on the internal workings of a system without those changes rippling out. This supports one of our key philosophies at Tag of “make it work and then make it good”. We can build a prototype, that meets the data contract, to test assumptions, get feedback and then we can improve that prototype into production ready code (or shelve it if it isn’t meeting the needs). Similarly this approach can also front load dependencies and allow more parallel work (like server and client being able to work independently once the data is designed).
The approach of passing in data to systems allows us to more easily change the source of the data without having to change the internal workings of the system itself. In the MovementSystem this could mean that the InputData fed to it comes from an AI Bot rather than an input device. Equally it could be we have dummy data that we create to enable testing - it’s much easier to mock data than it is to mock a full system.
An additional key benefit, from my perspective, is that I find it easier to read and understand code that flows linearly (while again acknowledging that readability is hard to measure directly). Humans are well conditioned to read text top to bottom (in most modern cultures at least), so having explicitly ordered system calls with explicit data flow allows me to read the coordinator like a story; “we get input data from the InputSystem, we pass that to the MovementSystem to calculate an updated position, we pass the updated position to the CameraSystem so the camera can frame the player”. With something like an event driven, or heavily interface driven, architecture I can find it hard to follow the flow without stepping through the debugger because I have to keep many more things in my head (e.g. what is the actual type of this interface).
Something to be careful of in this approach is that the coordinators don’t end up doing too much heavy lifting. Naturally the coordinators tend to be high traffic areas (often with multiple developers contributing) so we try and keep the logic inside of systems (and also design the data to minimise the transforms required to feed the data into systems). If you keep coordinators light on logic then conflicts tend to be trivial and easily resolved. You can reduce the chances of conflicts with a little bit of indirection, if you wish, by having the coordinator not deal in concrete data types but instead pass an object or interface that allows the systems to grab the data (meaning when the data structure changes only the provider and the using systems need to change and not the glue layer). But I don’t tend to make heavy use of that pattern simply because it can be harder to read at a glance.
#4 Enact global state changes centrally
If you’ve ever worked in Unity you will be familiar with how UI buttons operate. Essentially we attach a callback function to a button that is called in response to the button being pressed. If that callback is responsible for making a global state change such as showing a new screen, we might find if a player presses two buttons at the same time, two screens show up. Basically we need to have some system with access to all the information that is empowered to make those types of changes. Satellite systems (like a UI view controller) almost certainly don’t have all the information they need to avoid breaking the global state.
Instead of having satellite systems enacting the changes, they pass information to a central system (in our case the coordinator) and it leverages its access to the broader context to make the state changes correctly. In our UI case that would be knowing if there are other screens currently showing. If we think of the application as layers (#1 organise into layers and phases), information can flow bi-directionally but control flow should come from top down. There are multiple ways to achieve this sort of information flow without having too many circular dependencies. My preferred approach is to have the coordinator poll its systems for data (like in the diagram) and then have it use that data to trigger other appropriate systems (it’s more explicit and easy to follow). That way we avoid systems having dependencies on the coordinator. However, we can also use a message passing or event driven approach for this too (we also use a message queue in the coordinators in our codebases).
Tying this back to our theme of “responding to change”, centralising control flow or global state allows us to more safely expand the systems and their remits while still ensuring overall correctness of the app. Really we can think about this as splitting the responsibility of resolving into a central system that then allows many more contributing systems to be added over time. I often sum this principle up as “avoid having the tail wag the dog”.
#5 Model the behaviours and not the design domain
The “design domain” in our above example is ”We have a player controlled character (controlled via some input device) that moves around the world and the camera follows its position”, but would usually be a brief or design doc. This scenario outlines how the designer/user/product manager might think about the problem space. In my experience it isn’t always useful to model this 1:1 in our codebase (tempting though it may be). In the synopsis we described a “player controlled character” but you’ll see from the diagram there is no concept of a “player” mentioned. Let’s imagine for a minute we tried to more closely represent the design domain by adding a “Player” class and associating the behaviours of the player with that class (which in this case would be movement but in a more realistic example might include combat, levelling up, etc). Modelling the player as a type would result in a large class containing lots of complex (and probably unrelated) logic. When you have a file/class that is large and lacks cohesion it tends to have multiple developers working in it and a higher churn/change rate; this in turn can lead to more conflicts and more bugs, meaning there is more risk and resistance to making changes.
Instead of adding a “Player” class, we look to model along different boundaries that are better suited to our codebase. The first main guideline for splitting up the player is to create systems for each behaviour type. By splitting into smaller systems we reduce the responsibilities that any one system has and as a result reduce the amount of people, churn and low-cohesion coupling within a system - which makes it easier to change, remove, or add new systems. Another advantage of this is it makes it easy to have different entity types (players, enemies, NPCs) leverage the behaviours because the systems are decoupled from the types themselves. So as long as the data required by a system can be provided, any type can use it. ECS frameworks (like Unity Entities) are an example of this system based approach, however they come with a host of extra features that we haven’t needed so far and therefore tend to go with something simpler.
As well as splitting systems along behaviours, it is often advantageous to further divide systems based on churn/uncertainty and authors. Again it is about managing change and by isolating change we can iterate without having unintentional impacts on other areas. So if we have a system that has a couple of responsibilities that make sense to include together conceptually - but we find that one area is very stable (never changes) and one is changing frequently; it probably makes sense to split again. In doing so we isolate the churn and mitigate the risk of that churn polluting the stable part of the system. Same for authors. If we have a system where certain teams or individuals are changing one part and a different group is changing another - it probably makes sense to split to avoid conflicts and bugs that crop up in the communication gaps between teams. In terms of uncertainty - if we have experimental parts of a module, or things we are unsure of, it can be wise to isolate those as uncertainty tends to lead to a lot of churn and change. In certain cases it may even make sense to introduce a little bit of code duplication if it allows this sort of separation - particularly things like boilerplate code. When both systems are stable - we can always look to recombine and remove the duplicate code.
The dependency injection problem
Dependency injection is another term which has taken on lots of different meanings. I use it in the simplest sense of how we pass dependencies into systems that need them.
One of the things I pushed really hard on in past projects was having very explicit dependency management - so literally we push all dependencies into systems and we don’t use any “pull models” like DI frameworks or stuff like singletons. The feedback (and by my own admission) is that we took that model too far. In my head it was supposed to improve readability by showing dependencies explicitly and avoid an explosion of dependencies by introducing a little bit of friction whenever we needed to add one. In practice, because of our hierarchical finite state machine of coordinators, it meant routing dependencies into states just so those states could pass the baton onto another state; and it became quite rigid in terms of moving “phases” around as we had to reconfigure the plumbing..
One of the teams more recently made a proposal that I think addresses this issue while retaining the original spirit of the initiative. That is we can use the “pull model” via a service manager/DI framework (or even singletons shudder) inside a coordinator but we inject explicit dependencies (or containers of dependencies) into systems. So the coordinator can easily grab the dependencies needed by the systems and then forward them in (afterall the coordinators are the glue layer so we expect them to have a number of dependencies). The advantage of this is that we can reconfigure the “states”/”phases” of the application without having to rebuild the dependency chains but we still have enough of the friction/explicitness at the system level that means systems don’t start to talk to each other directly - keeping their behaviours and impact more isolated.
So in effect this adds rule #6 (or maybe just #1a) - “We can pull within coordinators but push into systems”.
The case study
One of the examples that jumps to mind when I think about reconfigurability (and it was a pretty extreme example) was on a project that Tag was working on around 2016. We had designed the codebase around encapsulating data to make sure that only systems that needed the data had access to it (under the premise that it would be safer because other systems couldn’t accidentally change the data or cause conflicts). We had very tight ownership between systems and the data and the systems were pretty much modelled on the design domain. It looked a little bit like this (it was actually a lot bigger than this but just pruned to what is relevant for the example):
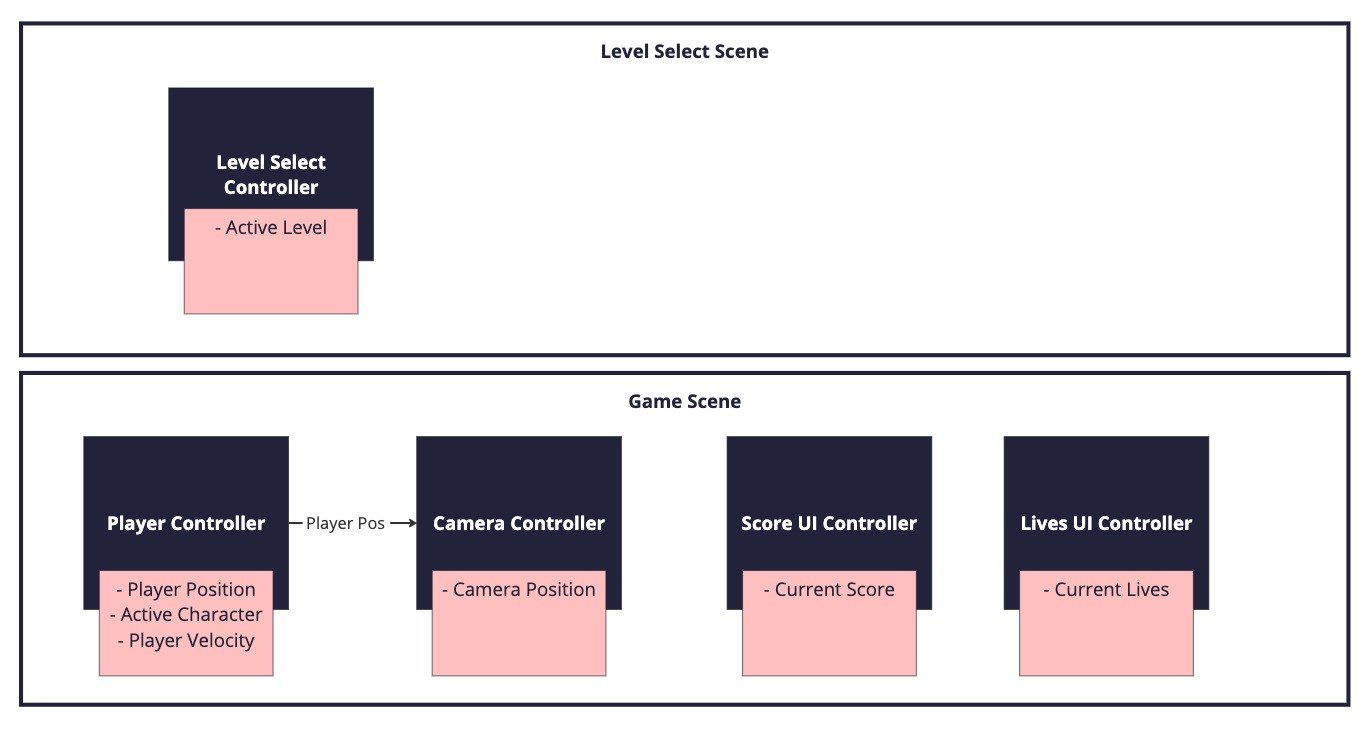
And then came the day when the product manager delivered us the telemetry spec. This spec outlined the analytics events that we wanted to track and the data that needed to be supplied with each event; and the spec cut right across all our encapsulation boundaries.
For example, here was one of the events:
Select Character Event
Selected character
Level being played
Current score
Current lives
As you can see from the diagram, all this data was encapsulated (hidden) in different systems. The player controller was the obvious candidate to trigger the event (as it was responsible for responding to character selection) but it only had access to a fraction of the data that was needed by the event. And it’s perfectly understandable why we didn’t think this data would have any relation to each other, but equally understandable why PM wanted this data bundled together, to understand the context in which players picked particular characters to help inform future product decisions. It would have been difficult for the programming team to have anticipated or foreseen these requirements during initial planning without that telemetry spec existing.
The solution we came up with to solve this was a little bit of a hack and actually turned out to be quite an expensive hack performance wise. It was two-fold, firstly, we ended up exposing lots of systems to the analytics system so that it could pull much of the data it needed (which meant turning a lot of systems into singletons and then we had the dependency explosion once it was easy for people to access systems anywhere). Secondly, we created the concept of micro events that could be used to send small pieces of data to the analytics system. Each event would listen for the data and build up its own package - once it had all the data it needed, including the trigger, it would be sent to the analytics backend. So for example we had a SelectCharacterEvent that listened for data, the LevelSelectController would send a micro event with the selected level, the PlayerController would send a micro event for the selected character (and the trigger) and the SelectCharacterEvent would then pull the score and lives from the newly created singletons. This was pretty slow as all events were listening for all data all the time to figure out what they needed! It was also prone to out of order issues if the micro event orders were changed - meaning events sometimes wouldn’t be sent as not all the data had been received before the trigger.
It was a really brittle system (and perhaps there were better workarounds) but fundamentally the design of what we needed the application to do had changed and our codebase was not equipped to respond. If I were doing that game again today I might structure it like this instead:
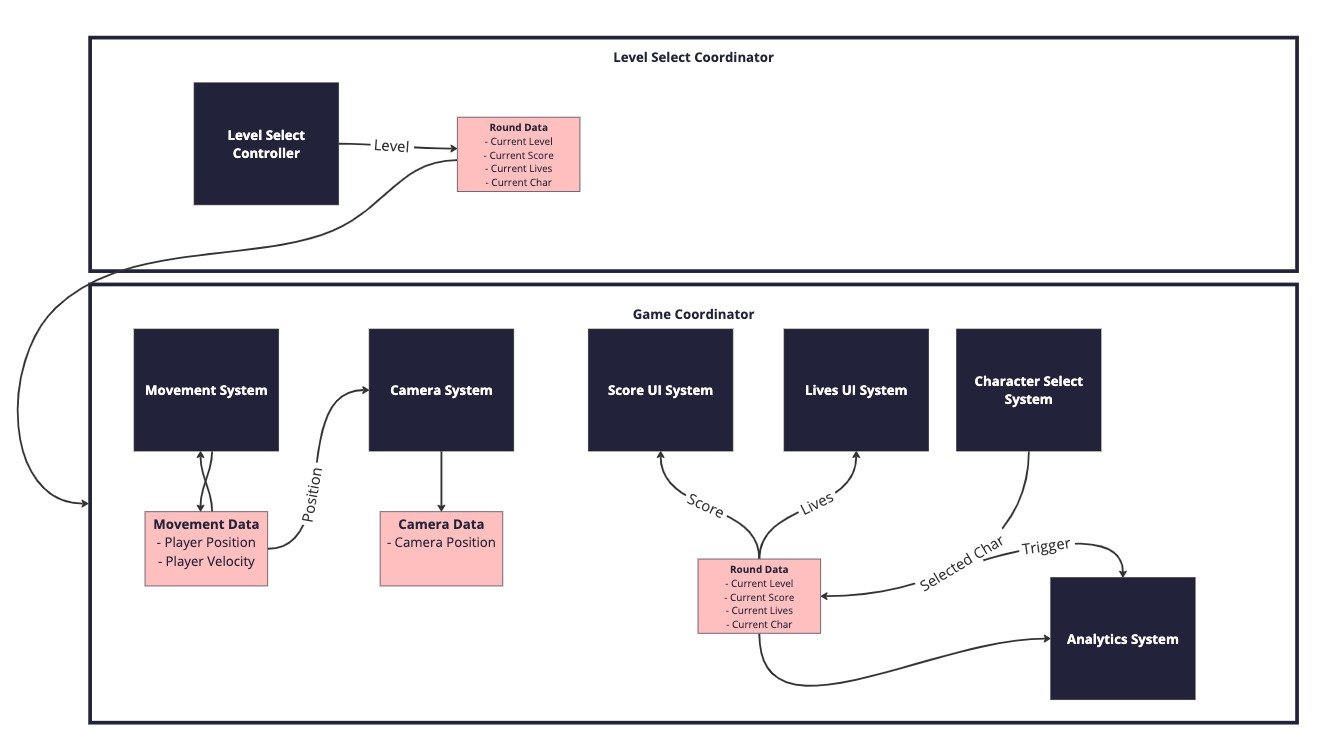
In the revised diagram above, the analytics events would typically be sent from the coordinators and they would leverage their access to the central databases to provide the relevant data. If you imagine the analytics system not existing at first, you should hopefully be able to see how trivial it would be to add and indeed to add more analytics events. The RoundData could be injected into the coordinator (which makes sense in this case as the phases are linear) but could equally be available globally or exist in a root coordinator. (Also in real life I’d probably split round data up once I better understood the data usage patterns).
Final thoughts
I’m certain there are dozens of details that I’ve missed from this overview that would make it tricky to actually apply the guidelines wholesale to your own specific applications; but I hope the overall gist came across and that you can see some of the positives and some of the tradeoffs that are made in this approach. Everything in programming is about tradeoffs, there are very few ideal scenarios so it’s important to make sure we understand what those tradeoffs are and make very considered and deliberate decisions about what tradeoffs we are willing to make based on the objective needs of our product.
Fundamentally architecture is not something that can be done on paper, up front and it never changes. Architecture cannot be rigid if we want to support the product and its changing goals. We need the actual feedback of writing code and we need to accept that change is inevitable as we uncover unknowns and surprises, and as we get feedback that helps us inspect and adapt. Being responsive to change in architecture is about reducing the cost of not only changing the internals of a module but also in changing the relationships between modules. And that is what the principles above try to do.
I would love to hear about architectural approaches that have worked for you and your teams and the guidelines your team has in place to help (and of course the tradeoffs you’ve been willing to make in service of them).
Further reading / watching
Write Code that is Easy to Delete - A great blog post that proposes the best way to have an adaptable codebase is to make it so modules are easy to remove and replace. Has some concrete advice for how best to split up a codebase.
The Architecture of Uncertainty - A video presentation that does a great job of articulating the fear of change and that architecture does not mean rigid plans we do upfront that never change. Talks about architecting around the cost of change and the impact of dependencies.